做 Apache Kafka 迁移时,最难熬的通常不是启动同步任务,而是切客户端那几个小时。旧集群还在写,新集群也开始接流量;一批 Producer 已经改了 bootstrap.servers,另一批还没改;Consumer group 的 offset 到底该从哪里继续;Flink checkpoint 里的位点切到新集群以后还算不算数。很多迁移计划把精力放在“数据能不能同步过去”,但停机窗口和回滚风险,往往卡在这些切流细节上。
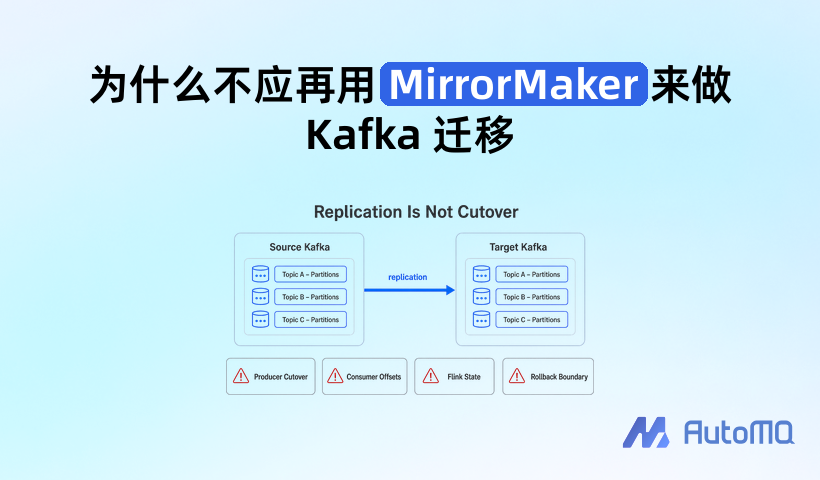
把 Kafka 迁移理解成“上一套 MirrorMaker 2”,问题通常从这里开始。MirrorMaker 2 是一个成熟的跨集群复制工具,它擅长 replication;零停机 Kafka 迁移要处理的是 cutover。两件事挨得很近,但工程风险完全不同。
MirrorMaker 2 做对了什么
MirrorMaker 2 不该被一棒子打死。它基于 Kafka Connect 构建,用 Connector 的方式复制 Topic 数据、配置、ACL 和 Consumer group offset,也能把跨集群复制纳入 Connect worker 的扩展和监控体系。对于长期运行的复制任务,它仍然是 Kafka 生态里很自然的选择。
它适合的场景通常很明确
- 异地复制与灾备:把一个集群的数据持续复制到另一个 Region,用于容灾、审计或下游分析。
- 数据聚合:多个业务集群的数据汇聚到中心集群,供离线或实时分析使用。
- 混合云同步:在自建 Kafka、云上托管 Kafka、不同云厂商之间做持续数据同步。
- 读侧扩展:把一部分消费压力转移到目标集群,避免所有下游都压在生产主集群上。
这些用法的共同目标,是让另一边持续拥有一份可用的数据副本。只要数据能复制、lag 能观测、异常能重试,MirrorMaker 2 就能交付价值。Kafka 迁移不一样,它要求业务在某个时刻把目标集群当成新的生产集群,而不是一份备用副本。
复制完成,不等于迁移完成
用 MirrorMaker 2 做迁移时,流程在纸面上很顺:建目标集群,启动复制任务,等目标集群追上源集群,再把客户端切到新集群。前半段通常没那么吓人。同步任务在跑,监控上能看到 lag 下降,团队很容易觉得“迁移已经差不多了”。
压力从切 Producer 开始。只要源集群还在接收新写入,目标集群就只能继续追;如果一部分 Producer 写源集群,另一部分 Producer 写目标集群,两个集群就可能出现写入分叉。为了避开分叉,团队往往会停写、等复制 lag 清零、再把 Producer 改到目标集群。到这一步,“迁移”就变成了维护窗口:业务能不能停、停多久、谁来确认 lag 真的清零、失败后怎么退回,都会变成上线会议里的硬问题。
Consumer 切换也不只是改一个地址。Kafka 的消费进度是按照 Topic、Partition、Offset 组织的,迁移工具必须回答一个具体问题:同一个 Consumer group 在目标集群应该从哪个 offset 继续消费?如果目标集群的 offset 与源集群不能保持一致,就需要做 offset translation。这个转换在普通消费应用里已经需要谨慎处理;到了 Flink、Spark Streaming 这类把消费位点纳入自身 checkpoint 或 state 的系统里,问题会更尖锐。应用并不一定依赖 Kafka 内部的 Consumer group offset,它相信的是自己状态里保存的位点。
Kafka 迁移最危险的错觉,是把“目标集群有数据”理解成“业务可以安全切过去”。前者是复制状态,后者是生产状态。
MirrorMaker 2 的短板也出在这里:它围绕复制链路设计,不围绕业务切流设计。复制链路可以告诉你数据从 A 到 B;迁移系统还必须告诉你写入何时切、消费何时放行、offset 如何保持、失败后如何回滚。
MirrorMaker 2 的 offset 问题,为什么会放大迁移风险
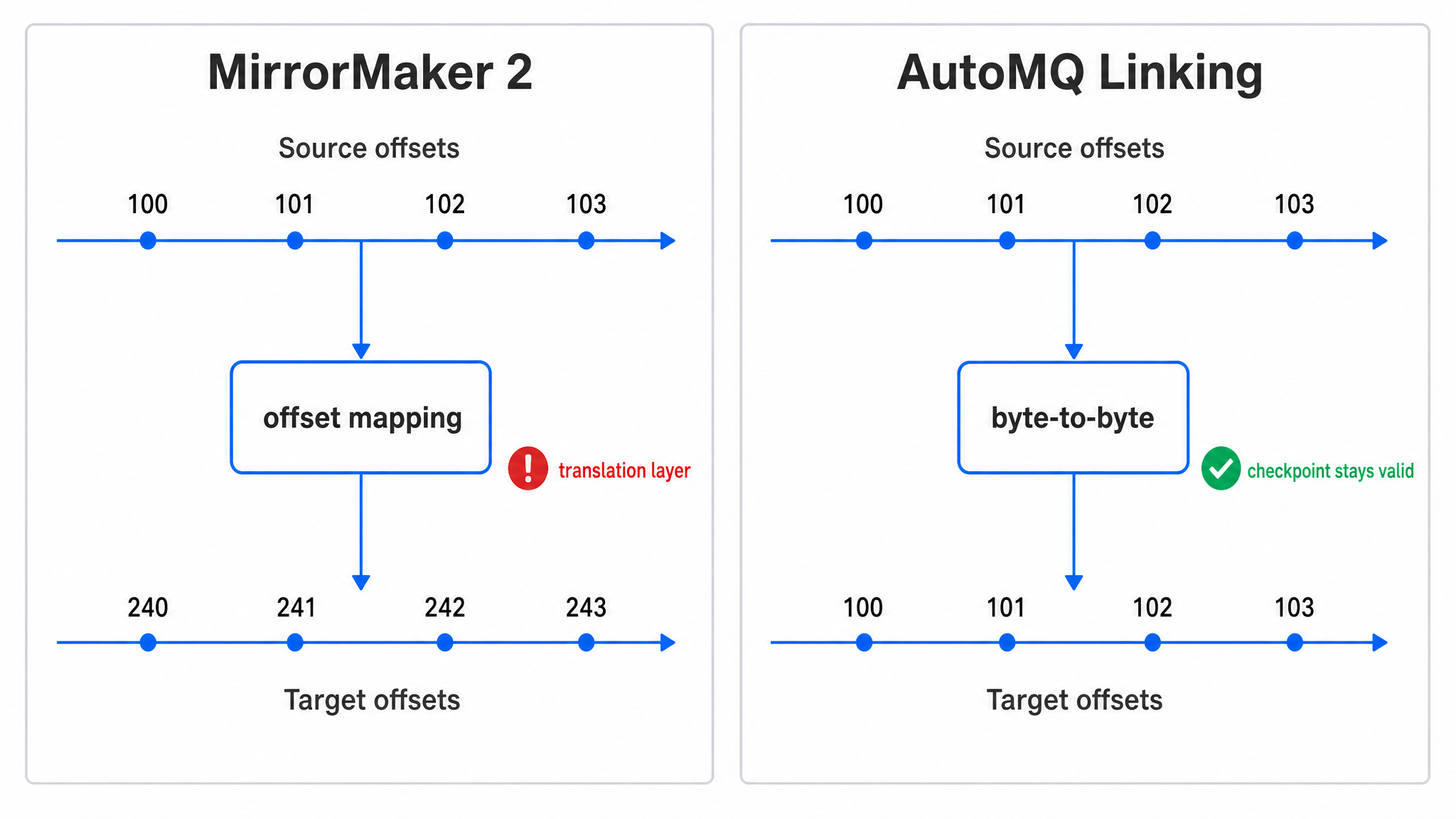
Kafka 的 offset 看起来只是一个递增数字,但它在迁移里承担了业务连续性的语义。Consumer 不是在消费“第几条消息”这个抽象概念,而是在某个 Topic Partition 的某个 offset 之后继续处理。如果迁移后 offset 发生变化,哪怕数据内容完全一致,消费系统也需要一个映射关系才能知道自己该从哪里恢复。
MirrorMaker 2 会同步 Consumer group offset,并维护源集群与目标集群之间的 offset 映射。这个设计适合跨集群复制,因为目标集群的日志不是源集群日志的原地延伸,复制过程中还可能涉及 topic alias、metadata 更新和独立的目标端 log append。可一旦进入迁移,offset mapping 就成了恢复路径上的“翻译层”。越靠近恢复路径,翻译层越让人紧张。
翻译层会带来几类实际风险
- 切换时机变复杂:Consumer group offset 的同步有周期和条件,迁移窗口里需要确认源端进度、目标端映射和复制进度同时满足要求。
- 重复消费或跳过消费的风险更难排查:一旦迁移后结果不符合预期,团队需要同时检查源 offset、目标 offset、offset sync topic 和应用自身状态。
- 外部状态系统不一定适配:Flink、Spark Streaming 等应用可能把 Kafka 位点写在自己的 checkpoint 或 state 里,Kafka 内部 Consumer group offset 同步并不能自动修复这些外部状态。
- 回滚路径更脆弱:如果切到目标集群后又写入了新数据,源集群和目标集群的 offset 与数据边界就需要重新对齐,回滚不再是“把地址改回去”那么直接。
这里不是实现质量问题,而是设计目标不同。MirrorMaker 2 服务的是跨集群复制,所以可以接受目标集群拥有自己的 log 位置,再用映射把两边接起来。零停机迁移追求的是另一件事:让目标集群尽量像源集群的连续延伸,客户端和状态系统不用理解中间发生过一次集群替换。
Kafka 迁移需要的是切流平面
把迁移拆开看,至少有两条路径。第一条是数据复制路径:历史数据和增量数据如何从源集群到目标集群。第二条是业务流量路径:Producer 写到哪里,Consumer 从哪里读,失败时流量如何退回。很多迁移事故不是数据复制彻底失败,而是业务流量缺少系统化控制。
迁移工具需要回答这些问题:
- Producer 是否可以分批切换,而不是一次性停写?
- 已经切到目标集群的 Producer 写入,是否还能被源集群 Consumer 继续消费?
- Consumer group 没有完全切完之前,目标集群是否会阻止重复消费?
- 源集群和目标集群的 Topic Partition offset 是否可以保持 1:1 对齐?
- Flink checkpoint、Spark state 这类外部状态是否能在切换后继续有效?
- 迁移失败时,是否有清晰的回滚边界,而不是临时做数据修补?
其中只有一部分属于“复制”。更多问题属于切流平面:迁移期间同时控制写入路径、读取路径、消费进度和回滚路径。MirrorMaker 2 可以作为复制链路的一部分,但它没有把这些切流动作变成一个完整的迁移协议。
按这个标准再看迁移工具,问题就变成了:目标集群在迁移期间能不能承担一个中间角色?它需要接收已经切过来的 Producer 写入,又不能让源集群上的 Consumer 丢掉完整数据;它需要同步历史数据,又要让 offset 继续被有状态应用识别;它还要允许分批切换,而不是把所有风险压到一次停机窗口里。
AutoMQ Linking 补上的,是这层迁移协调
AutoMQ Linking 正是按这个问题设计的。它面向从 Apache Kafka 或兼容 Kafka 协议的发行版迁移到 AutoMQ 的场景,不把迁移拆成“先复制、再停机切换”两件事,而是把数据路径和流量路径放进同一套迁移流程。业务代码不需要改,客户端按批次滚动切换。
第一层是 byte-to-byte replication。源集群 Topic Partition 的消息复制到目标集群后,offset 保持对齐,目标集群不需要拿一套新的 offset 再去做翻译。对于依赖 Kafka offset 恢复状态的系统,这个差异很实际;对于 Flink 这类把位点写入 checkpoint 的系统,它关系到原有状态能不能继续用,而不是被迫重置或从头处理历史数据。
第二层是 Producer proxy path。迁移 Producer 时,团队可以分批把 Producer 的访问地址切到 AutoMQ;已经切过来的 Producer 写入 AutoMQ 后,AutoMQ 在迁移阶段把写入代理回源集群。源集群上的 Consumer 仍然能看到完整的新写入,没切的 Producer 也继续写源集群,业务不必为了避免分叉而停写。
Consumer 侧也不能只靠改地址。Consumer group 还没有完成整体切换时,如果目标集群立即允许新 Consumer 读取,就可能和源集群上的旧 Consumer 形成重复消费。AutoMQ Linking 会在迁移过程中协调 Consumer group:等同一个 Consumer group 从源集群下线并完成切换后,再同步消费进度并放行目标侧消费。这一步不醒目,但很要命,很多“看起来已经同步完成”的迁移就栽在这里。
MirrorMaker 2 vs. AutoMQ Linking:迁移语境下的差异
按迁移目标来比较,两者的边界会更清楚。
| 维度 | MirrorMaker 2 | AutoMQ Linking |
|---|---|---|
| 核心定位 | 跨集群复制、灾备、聚合、同步 | 面向 AutoMQ 的零停机 Kafka 迁移 |
| 数据路径 | 基于 Kafka Connect 的复制链路 | Byte-to-byte replication,保持 offset 对齐 |
| Producer 切换 | 通常需要停写、等 lag 或自行设计双写协调 | 支持 Producer 滚动切换,并在迁移阶段代理写回源集群 |
| Consumer 切换 | 依赖 Consumer group offset 同步和 offset translation | 同步消费进度,并通过 Consumer group 协调避免重复消费 |
| Flink / Spark 状态 | 外部状态里的位点可能无法被 Kafka offset sync 自动覆盖 | 通过 1:1 offset consistency 提高状态连续迁移的可行性 |
| 回滚 | 切到目标后若发生新写入,需要人工处理源目标差异 | 迁移阶段写入仍可代理回源集群,回滚边界更清晰 |
| 运维模型 | 需要部署和运维 Connect worker、Connector、内部 topic | 由 AutoMQ 侧提供迁移能力,随目标集群管理 |
MirrorMaker 2 的位置仍然在复制、容灾和同步。任务一旦变成“把线上 Kafka 生产业务迁到新集群,并且尽量不影响业务”,团队要管理的对象就从数据副本变成了生产流量。工具边界看错了,停机窗口、offset 校验和回滚预案都会落回人工流程。
什么时候还可以用 MirrorMaker 2
判断要回到迁移目标。如果你的目标是持续复制一份数据给另一个集群,目标端主要用于灾备、分析、汇聚或只读消费,MirrorMaker 2 仍然合理。它的生态成熟,部署方式清楚,和 Kafka Connect 体系结合紧密,团队也容易找到已有经验。把它用在这些场景里,问题通常是容量规划、复制延迟和运维稳定性,而不是业务切换语义。
但如果你的目标是生产集群迁移,尤其是这些条件同时出现,就不应该再把 MirrorMaker 2 当成默认方案:
- 业务无法接受统一停写窗口,Producer 必须滚动切换。
- Consumer group 数量多,且不能接受大量手工 offset 校验。
- 存在 Flink、Spark Streaming、Kafka Streams 等有状态消费任务。
- 迁移后需要保留快速回滚能力,而不是“切过去就只能往前走”。
- 迁移范围要按 Topic、Consumer group 分批推进,而不是一次性大爆炸。
这些条件在生产环境里很常见。Kafka 往往处在数据链路中心,上游服务、实时计算、监控告警、用户行为分析、风控链路都可能依赖它。越是核心的 Kafka 集群,越不能把迁移建立在“找个低峰期停一下写入,然后希望一切顺利”这种假设上。
该换掉的是迁移模型
MirrorMaker 2 的问题不是“不能复制”。它的问题在于,Kafka 迁移已经不能只按复制问题来建模。复制工具关注数据怎么到另一边;迁移工具要关注业务怎么切到另一边。前者关心 lag,后者还要关心写入路径、消费进度、状态恢复和失败回退。
标题里的“不要再用”,不是说 MirrorMaker 2 没有价值,而是不要再把 Kafka 迁移默认设计成一条复制链路加一次停机切换。这个模型在小规模、低依赖的集群上可能够用;到了有状态计算、多个 Consumer group、持续写入和严格可用性要求的生产环境,它会把最难的部分留给人工协调。
Kafka 生产迁移需要把数据复制、Producer 切换、Consumer 协调、offset 连续性和回滚路径放在同一套流程里。MirrorMaker 2 可以继续做它擅长的复制;生产迁移应该交给为迁移而设计的工具。
如果你的团队正在评估从 Apache Kafka、MSK 或 Confluent 迁移到 AutoMQ,可以先从一组非核心 Topic 和 Consumer group 开始验证 AutoMQ Linking 的迁移路径,再逐步把核心业务纳入计划。想看它在你的 Kafka 集群里怎么落地,可以开始试用 AutoMQ,用真实迁移任务验证 Producer 滚动切换、Consumer group 协调和 offset 连续性。