介绍
在云端运行 Apache Kafka 面临三大核心工程挑战:低延迟性能严重依赖本地磁盘、跨可用区(AZ)流量成本高昂,以及计算与存储紧密耦合导致的弹性不足。为此,AutoMQ 基于 Amazon FSx 与 S3,打造了一套全新的 Diskless Kafka 方案。本文将详细解读 AutoMQ 如何通过重构存储层,在完全兼容 Kafka 协议的同时,实现亚 10ms 的写入延迟,交付一个高性能、运维简便且极具成本优势的云原生 Kafka。
注: 如无特殊说明,下文 AutoMQ 均指 AutoMQ BYOC 版本。
FSx for NetApp ONTAP
在深入探讨 AutoMQ 的实现细节之前,我们先了解一下 Amazon FSx for NetApp ONTAP (以下简称 FSx),这是 AutoMQ 在 AWS 上实现亚10ms性能的核心基石。
FSx 是一项全托管服务,它基于 NetApp 广受欢迎的 ONTAP 文件系统构建,提供高可靠、可扩展、高性能且功能丰富的文件存储。
FSx 旨在访问 SSD 存储数据时,提供稳定的亚 10ms 延迟。它能为每个文件系统提供高达数十 GB/s 的吞吐量,以及数百万级的 IOPS。这使得包括 Oracle 和 Microsoft SQL Server 在内的许多数据库都能部署在它上面。
FSx 利用 HA Pair(高可用对)机制来确保数据的可靠性。每个 HA Pair 由一个主(Active)文件服务器和一个备(Standby)文件服务器组成。每一次写入操作在向客户端返回响应之前,都必须在两个节点上完成持久化,从而确保即便任意一个文件服务器发生故障,FSx 依然拥有完整的数据。
FSx HA Pair 提供两种类型:单可用区(Single-AZ)和多可用区(Multi-AZ)。在 Multi-AZ 模式下,FSx 能够容忍可用区级别的不可用故障。更具吸引力的是,Multi-AZ 模式在同一区域内的任意可用区进行访问时,不收取跨区流量费。
FSx 的跨 AZ 成本杠杆
接下来让我们看看最有趣的部分:在 AWS 上购买一个 1536 MBps 的第二代 Multi-AZ 文件系统,其月费用为 4108 美元。
利用该 FSx 作为跨区通信的中继,即在 Zone 1 写入数据,随后在 Zone 2 读取并删除。假设传输速度为 1400 MBps,则单月可传输的数据总量达 3,543,750 GB。
如果这 3,543,750 GB 的数据直接通过跨区网络传输,费用将高达 3,543,750 * 0.02 = 70,875 美元,这相当于 FSx 成本的 17 倍。
这一惊人的成本差异,彻底颠覆了传统的云端架构选型逻辑:FSx 不再仅仅是一个存储服务,而是成为了攻克“跨区流量高昂”这一顽疾的关键钥匙。
AutoMQ 敏锐地捕捉到了这一巨大的“架构红利”。我们以 FSx 为基石,将这一“高性能 + 零跨区费”的存储特性转化为系统级的竞争优势,最终打造出了这款写入延迟低于 10ms、且极具成本竞争力的 Diskless Kafka。
架构
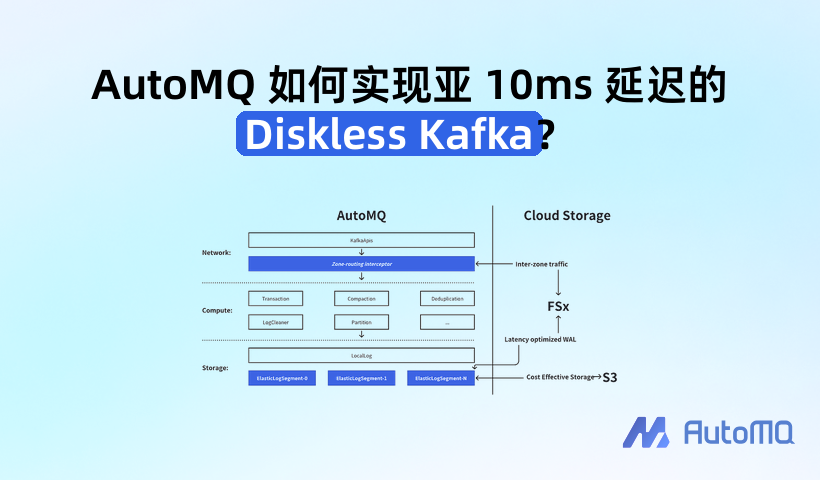
有了 FSx 这一理想的存储基石,接下来的挑战是如何构建一个云原生的 Kafka。 为了找到最优的实现路径,我们先深入解析 Apache Kafka 的系统分层,从而明确改造的切入点。
Apache Kafka 的三层结构
Apache Kafka 由以下三个部分组成
-
网络层负责处理新建客户端连接、解析请求、根据 API_KEY 调用对应的计算层逻辑,并将响应返回给客户端。
-
计算层涵盖事务、日志压缩和去重等逻辑。它沉淀了 Apache Kafka 十余年来积累的新特性、客户端兼容性改进及缺陷修复,占据了 Apache Kafka 代码库 98% 的代码量。
-
存储层负责将无限长的 Log 切分为有限长度的数据段(即 LogSegment),并将这些 LogSegment 映射到本地文件系统中的具体文件。
如果要从零开始构建一个 100% 兼容的 Apache Kafka 产品,不仅需要适配 Apache Kafka 现有的 1000 多个 KIP,还得在未来持续跟进社区的新特性与修复,这几乎是一项不可能完成的任务。
因此,AutoMQ 选择基于 Apache Kafka 的分支进行云原生改造,从而实现亚 10ms 延迟的 Diskless Kafka。
AutoMQ 的改造切入点
-
100% 兼容 Kafka: AutoMQ 保留了计算层绝大部分代码,从而确保其 Kafka 协议处理行为与 Apache Kafka 严格一致。
-
零跨区流量AutoMQ 在 KafkaApis 之下增设了一个区域路由拦截器(zone-routing interceptor),专门用于拦截 Produce 和 Metadata 请求。这一机制使得客户端只需与同一可用区内的 Broker 进行通信,从而实现了 Kafka 客户端的零跨区流量。
-
Diskless 架构AutoMQ 将 Apache Kafka 的最小存储单元 LogSegment 替换为云原生实现 ElasticLogSegment。
ElasticLogSegment 会将 Kafka 消息(Records)以亚 10ms 延迟写入存储加速层 FSx,随即向客户端返回成功。而在后台,它会异步地将数据批量写入 S3。通过结合 FSx 和 S3 这两种云存储,AutoMQ 打造了一个兼具亚 10ms 低延迟与高性价比的 Diskless Kafka 方案。
消除跨可用区(AZ)流量
虽然 FSx 完美解决了数据复制层面的跨区成本,但在客户端接入层,原生 Kafka 的机制依然是成本杀手。要真正实现全链路的“零跨区流量”,我们必须打破 Kafka 传统的通信限制。
为了在 AWS 上实现零跨区流量,我们要防止 KafkaProducers 和 KafkaConsumers 与位于不同可用区的 Broker 进行通信。Apache Kafka 采用基于 Leader 的架构,即一个分区的 Leader 仅驻留在某一个 Broker 上。这意味着,如果来自其他可用区的 KafkaProducer 向该分区 Leader 发送消息,就会产生跨区流量。
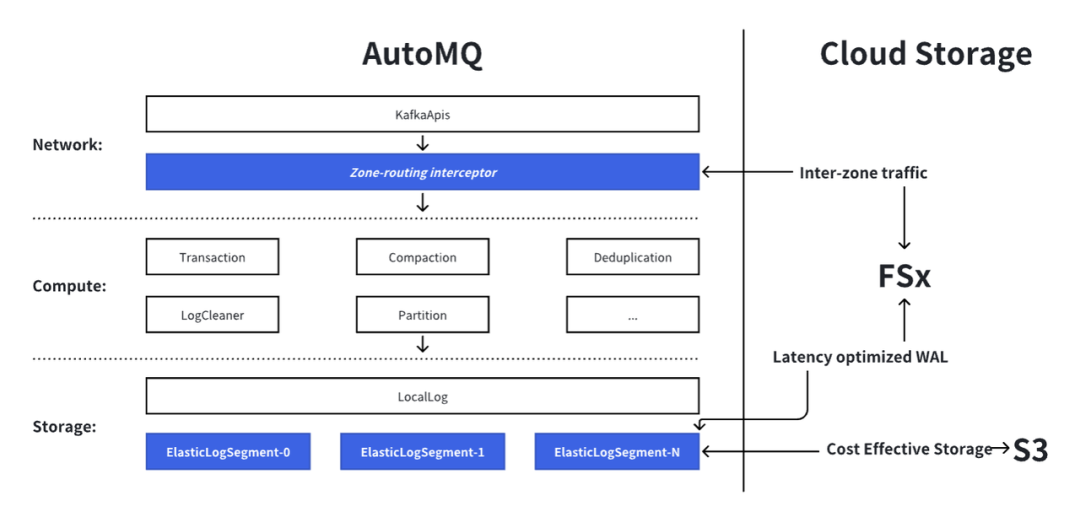
Main Broker 与 Proxy Broker
为了解决这一问题,AutoMQ 提出了 Main Broker 和 Proxy Broker 的概念:
-
Main Broker其行为和角色与 Apache Kafka 中的 Broker 保持一致;这仅仅是配合 Proxy Broker 而引入的一个概念。
-
Proxy BrokerProxy Broker 会镜像并同步 Main Broker 上所有分区 Leader 的状态,并伪装成对应的分区 Leader,从而为 Kafka 客户端提供 Produce 和 Fetch 服务。
每个 Main Broker 在其他所有可用区中都拥有一个 Proxy Broker。这使得位于任意可用区的客户端均能在本区内直接访问集群的所有分区。值得注意的是,“Main Broker”和“Proxy Broker”仅为虚拟角色概念;单个 AutoMQ 进程可以同时作为 Main Broker 运行,也可以兼任其他 Broker 的 Proxy Broker。
为了确保 Produce 和 Fetch 请求仅访问同一可用区内的 Broker,AutoMQ 利用区域路由拦截器来拦截 Metadata 请求。如果承载分区 Leader 的 Broker 不在客户端当前所在的可用区,拦截器会根据客户端的可用区信息,将 Metadata 响应中的 Broker 地址替换为客户端所在可用区内的 Proxy Broker 地址。
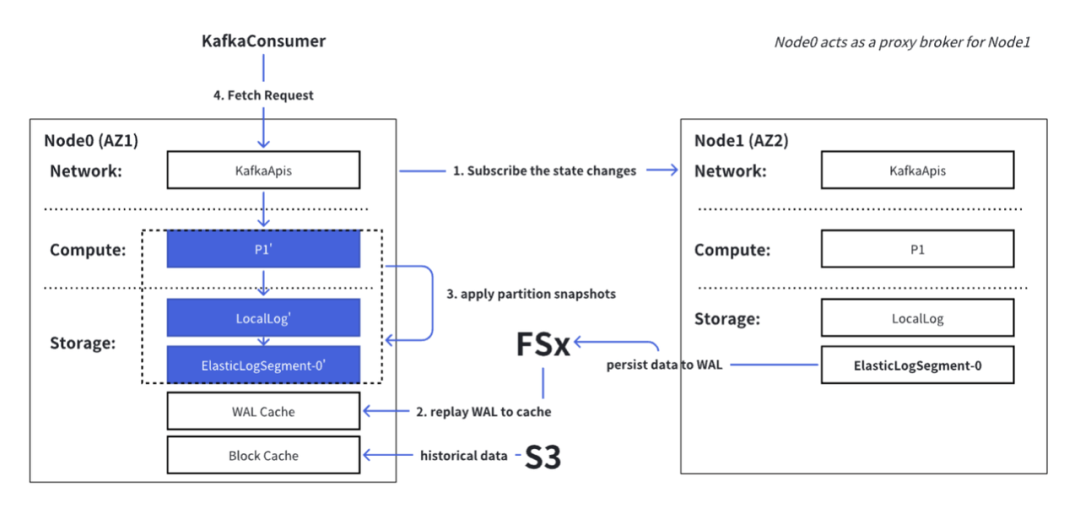
以附图为例:Node0 和 Node1 互为对方的 Proxy Broker,其中 P1 和 P2 的分区 Leader 分别位于 Node0 和 Node1 上。位于 AZ2 的客户端发起的 Metadata 请求,其返回的响应将被修改为 {P1 => Node1, P2 => Node1}。
通过上述机制,我们成功将客户端的连接“锁”在了本地可用区。然而,这只是完成了一半。既然 Proxy Broker 只是一个“伪装者”,当它接收到数以 GB 计的写入请求时,如何确保在不产生跨区数据传输的前提下,依然能像真正的 Leader 那样完成数据的持久化与强一致性确认?
写入路径
亚 10ms 区域对齐写入
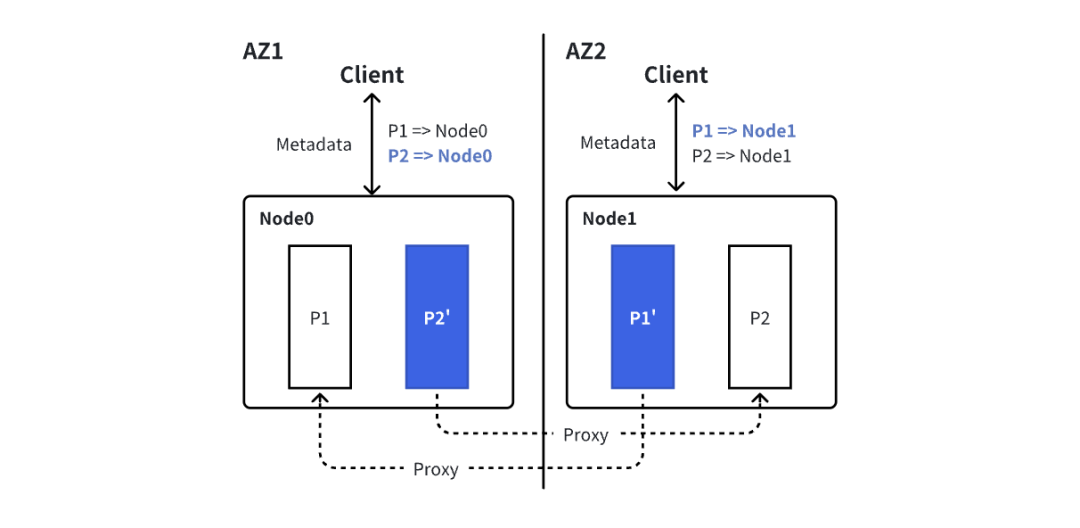
如果 KafkaProducer 目标分区的实际 Leader 不在当前可用区,本地 Proxy Broker 将充当分区 Leader 来处理 Produce 请求。虽然对于客户端而言,Proxy Broker 表现为分区 Leader,但在实际执行写入时,它仍需实际分区 Leader 的参与,以便进行数据有效性验证、去重、定序和存储。
为了在无需跨区传输大量数据负载的前提下实现低延迟跨区写入,AutoMQ 采用了一种轻量级的两阶段协议,利用 FSx 作为共享的低延迟缓冲区。
当任意可用区(AZ)的客户端发送 Produce 请求时:准备阶段(本地写入)
本地 Proxy Broker 将完整的请求数据直接写入共享 FSx 卷(位于同一区域),并记录数据位置。这一过程完全在客户端所在的可用区(AZ)内进行,且耗时仅为亚 10ms。
确认阶段(远程协调)
Proxy Broker 向 Main Broker(即真实的分区 Leader)发送一条极小的协调消息(约 100 字节),随后:
-
Main Broker 执行
Partition#appendRecordsToLeader,以完成数据校验、去重、定序和持久化等逻辑。 -
Record 数据被写入时延优化的预写日志(WAL,基于 FSx 实现),此时持久化即被视为成功。
-
为了降低 FSx 的写入开销,此处的持久化仅记录元数据(包括位置信息,以及在追加过程中分配的 Offset 和 Epoch)。
-
完整的 RecordBatch 仍缓存在 WAL 缓存中,供热数据读取及后台上传至 S3 使用。
-
将 ProduceResponse 嵌入确认结果中并返回给 Proxy Broker,随后由 Proxy Broker 将该结果转发给 KafkaProducer。
由于 FSx 是区域级共享的,且支持通过 NFS 从所有可用区访问,因此实际的 Record 数据无需跨越可用区边界,仅需传输极小的控制消息。相比 Apache Kafka,这一机制将跨区流量降低了 3 到 4 个数量级。
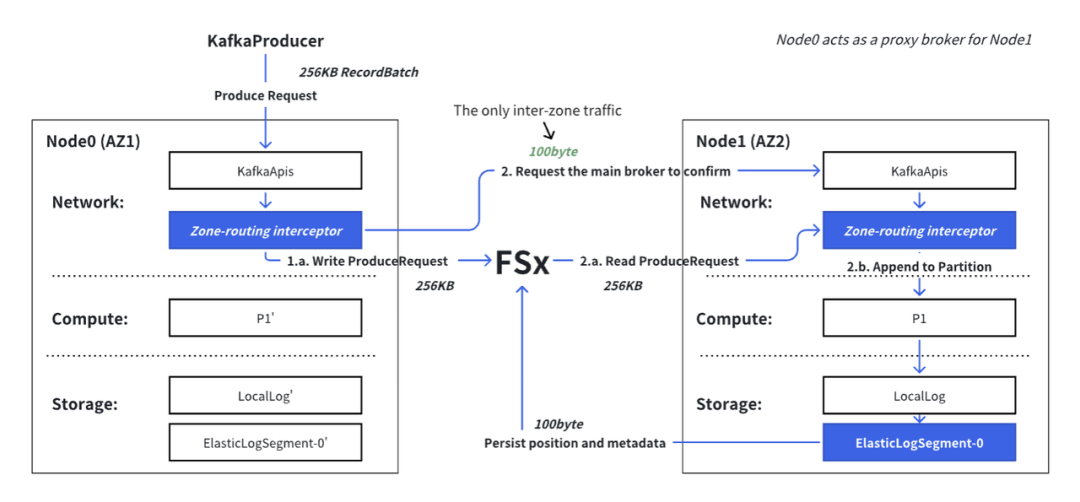
Produce 延迟构成
通过这个 Produce 处理流程,我们可以推导出 AutoMQ 中单个 ProduceRequest 处理时间的构成:
-
将 ProduceRequest 写入 FSx。
-
跨区请求确认 RPC:跨区 RPC 延迟 + 从 FSx 读取 ProduceRequest + 向 FSx 写入确认记录。
在 AWS us-east-1 区域,客户端侧的平均 Produce 延迟仅约 6ms。
高性价比存储
通过上述的写入路径,我们成功利用 FSx 实现了极致的写入性能。但你可能会问: FSx 性能虽好,价格却不菲,如果用来存海量历史数据岂不是天价?
这正是 AutoMQ 架构设计的另一大亮点:我们将 FSx 仅定位为“高性能写入缓冲区”,而将海量数据的存储重任交给了极其平价的 S3。
FSx 只承担热数据缓冲
FSx 的价格为每月每 GB 0.35 美元,而 S3 仅为每月每 GB 0.023 美元。为了优化存储成本,AutoMQ 因此仅将 FSx 用作持久化、低延迟的写入缓冲区,而将主要数据提交至 S3。
当 WAL 缓存中未上传的数据超过 500 MiB,或者距离上次上传已过 30 秒时,AutoMQ 会将 WAL 缓存数据(其中缓存了最近写入的完整 RecordBatch)提交到 S3。
S3 对象组织
AutoMQ 在上传数据前,会按 (Partition, Offset) 对数据进行重新分类和排序,形成两类对象:
-
如果某个分区的数据量超过 8 MiB,它将作为一个独立对象(StreamObject,SO)被上传。紧凑对象提高了读取历史数据的效率,而独立对象也有利于对具有不同 TTL(生存时间)的主题进行数据清理。
-
剩余分区的数据将被聚合写入一个单一对象(StreamSetObject,SSO),以避免 S3 API 调用频率随分区数量增长而呈线性上升。
-
数据上传至 S3 后,删除 FSx 中的数据。
借助此机制,一个具备 10 GBps 写入吞吐量、包含 50 个节点的 AutoMQ 集群,在 FSx 上所需的总空间不到 100 GB。
StreamSetObject(SSO)会在后台进一步合并(Compact),以提升冷读效率:小型 SSO 会被合并为大型 SSO,大型 SSO 则会被拆分为独立的 SO。
读取路径
至此,数据已经安全落盘:原本昂贵的“热数据”暂存在高速的 FSx 中,而海量的“冷数据”则经过整理沉淀到了平价的 S3 里。
那么,消费者如何能像访问本地磁盘一样,高效地读取这些分布在不同介质上的数据,同时依然保持“零跨区流量”?
实际上,FSx 和 S3 分别存储 AutoMQ 最近写入的数据和历史数据。两者均为区域级共享的云存储,任何 AutoMQ 节点都可以访问整个集群的完整数据。
与写入路径类似,AutoMQ 使用 Proxy Broker 模拟分区 Leader,并在所有可用区提供可用区对齐(Zone-aligned)的读取服务,以确保数据读取效率。Proxy Broker 之所以能够模拟 Main Broker,在于其镜像了 Main Broker 的状态:
-
Proxy Broker 持续订阅 Main Broker 的状态变更,包括 WAL 的 endOffset 和分区快照(High Watermark、LSO 等)。
-
Proxy Broker 首先从 FSx 中读取 Main Broker 的 WAL 数据,并将其回放到缓存中。
-
随后,它在本地应用分区快照。至此,Proxy Broker 完成了对 Main Broker 的状态镜像。
-
最后,Proxy Broker 可以直接从 WAL 缓存中将最新写入的数据返回给消费者,而历史数据则按需从 S3 读取并返回给消费者。
对比
至此,我们用一套架构同时实现了:FSx 的速度、S3 的价格以及零跨区流量。 这在实际生产中意味着什么?我们直接用测试的数据来说话。
测试场景
对于写入吞吐量 1 GBps、消费速率 1 GBps 且 TTL 为 3 天的场景,需配置 6 台 m7g.4xlarge 计算实例以及 2 × 1536 MBps 的 FSx 存储。具体成本细分如下:
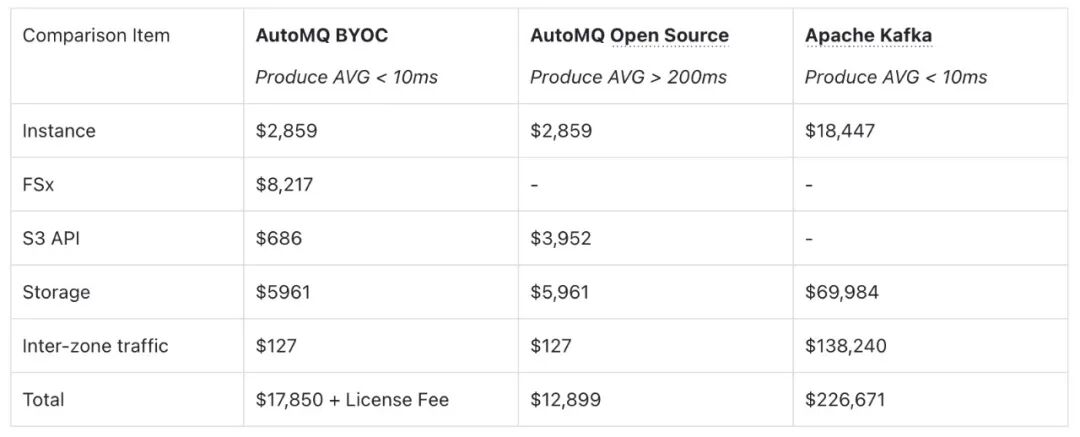
AutoMQ 开源版与 Apache Kafka 的数据引用自 AutoMQ 官网:AutoMQ vs. Apache Kafka Benchmarks and Cost。
结论
结论显而易见:你不再需要为高性能支付“天价”账单。相比传统架构,AutoMQ 在交付同等 <10ms 延迟体验的同时,实现了超过 10 倍的 TCO 缩减。
总结
AutoMQ 彻底重构了云端 Kafka 的生存法则。通过将 FSx 的极致性能与 S3 的极致成本完美融合,在保持 100% Kafka 协议兼容的前提下,交付了亚 10ms 的写入延迟与真正的零跨区流量成本。