
Kafka 的问题不是生态过时,而是存储架构在云上变重
Kafka 在云上变重,通常不是因为 Kafka 的生态过时了。Kafka 的客户端、协议、Connect、Streams、Admin tools 和运维经验,仍然是数据基础设施里最难替代的部分。问题更多出在存储假设上:broker 绑定本地磁盘,分区绑定具体节点,可靠性依赖多副本复制,扩缩容往往意味着数据迁移。这个模型诞生在数据中心时代,放到云上运行时,会把存储成本、跨 Availability Zone (AZ) 复制流量和运维复杂度一起放大。
Diskless Kafka 的吸引力就在这里。把持久化数据从 broker 本地磁盘迁到共享对象存储,broker 就可以更接近无状态计算节点:扩容不再等同于搬数据,故障恢复不再依赖本地副本,存储容量也不再被单台机器或云盘规格锁住。这个方向听起来很自然,但有一个前提容易被低估:用户想换掉的是本地磁盘架构,不是整个 Kafka 生态。
Diskless Kafka 的价值前提,是不让用户重建 Kafka 生态
用户依赖 Kafka,依赖的不是一个能收发消息的接口,而是 Kafka 多年沉淀下来的行为集合。Kafka 兼容性包括 API 版本、错误码、事务、幂等 producer、Consumer group、Log compaction、Admin tools、Connect、Streams、KRaft 元数据行为,也包括各种语言、各种历史版本客户端里的边界细节。一个系统如果只在 produce/fetch 这类主路径上表现得像 Kafka,生产环境里仍然可能在 compaction、事务、重平衡、旧客户端或工具链上暴露差异。
这些差异最后都会变成用户成本。应用代码要不要改?现有 SDK 能不能继续用?Strimzi、Connect、Streams、监控和运维脚本是否还能按原来的方式工作?灰度迁移时,如果新系统和原 Kafka 在某个边界行为上不一致,问题会出现在业务侧,而不是架构图上。Diskless Kafka 的成本优势只有在 Kafka 生态不被打断时才成立;否则,省下来的基础设施成本会被迁移、测试和长期维护风险吃掉。
长期兼容的关键,是不要重写变化最快的计算层
更难的是,兼容性不是一次性开发任务。Apache Kafka 的能力演进主要发生在计算层:协议 API、Coordinator、事务、Consumer group、KRaft、Admin API、新 KIP 和 bug fixes 都集中在上层语义。存储层当然也重要,但它相对稳定,并且正好是云上成本、弹性和数据迁移问题最集中的地方。这就带来一个关键的架构取舍:如果一个 Diskless Kafka 系统用 Go 或 C++ 重新实现 Kafka API,它就把自己放在 Kafka 变化最快、语义最复杂的位置上。
代码量级能把这个判断讲得更直观。Apache Kafka 已经演进超过 10 年,背后有 1,000 多位贡献者和 1,019 个 KIP;截至 2024 年 2 月 23 日的一个统计版本,Kafka 代码库接近 886,000 行。这里面,处理 API 协议和上层功能的计算层约占 98%,负责持久化消息的存储层只有约 1.97%,也就是 17,532 行代码。如果目标是云原生化 Kafka,重写计算层是在最复杂、变化最快的地方追赶上游;替换存储层,才是在问题最集中、边界也更清楚的位置动手。
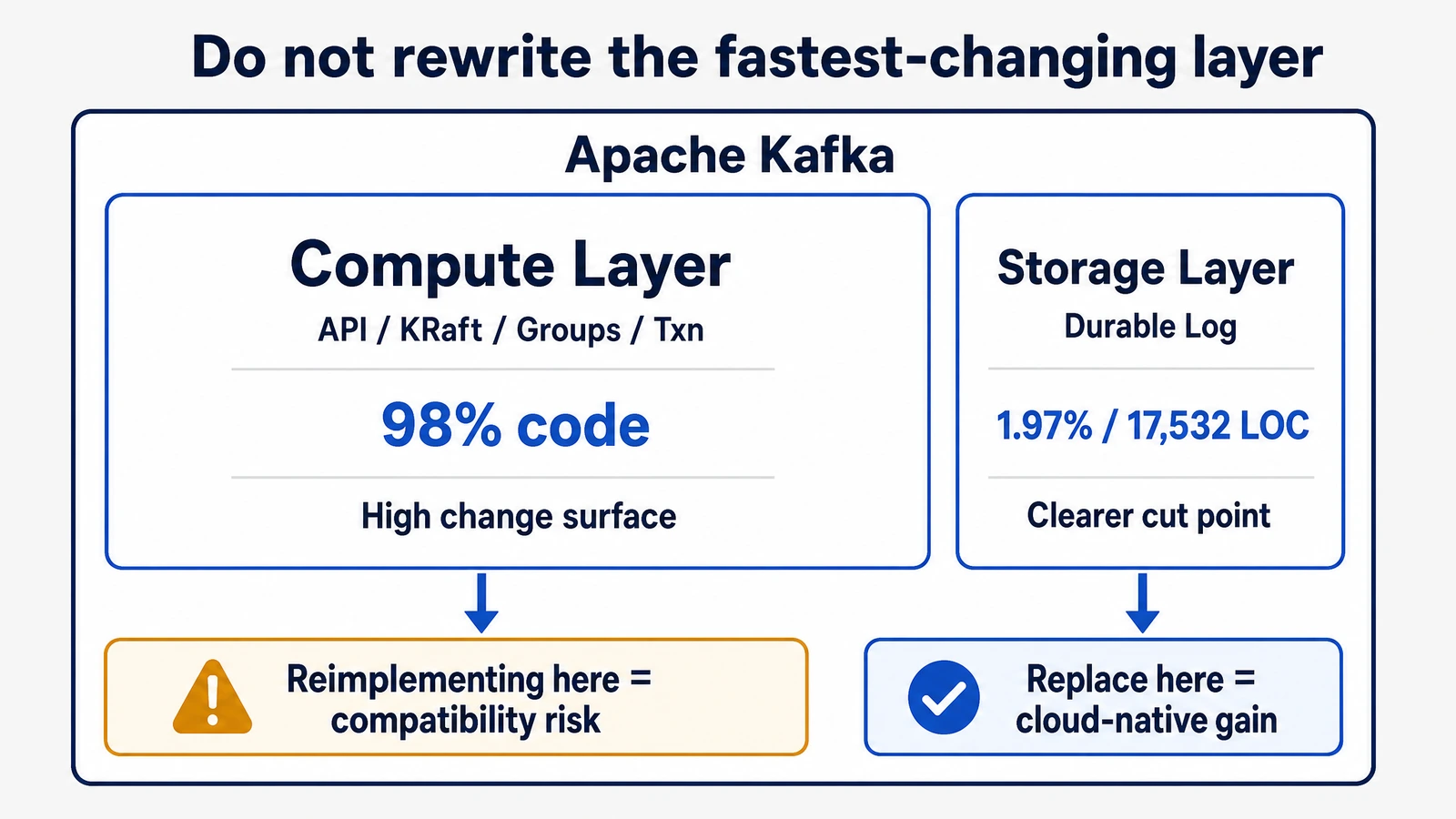
重写 API 当然不是做不到,问题在于长期代价很高。上游 Kafka 新增 API、调整旧 API 行为、修复边界 bug 时,重写实现都需要重新开发、测试和验证。更麻烦的是,很多兼容性问题不会表现为“有没有这个 API”,而是同一个请求在异常、重试、版本协商、事务状态和 group rebalance 里的细微行为差异。对用户来说,这类差异最难评估,也最不适合在生产迁移后才发现。
AutoMQ 为什么把兼容性放在第一位
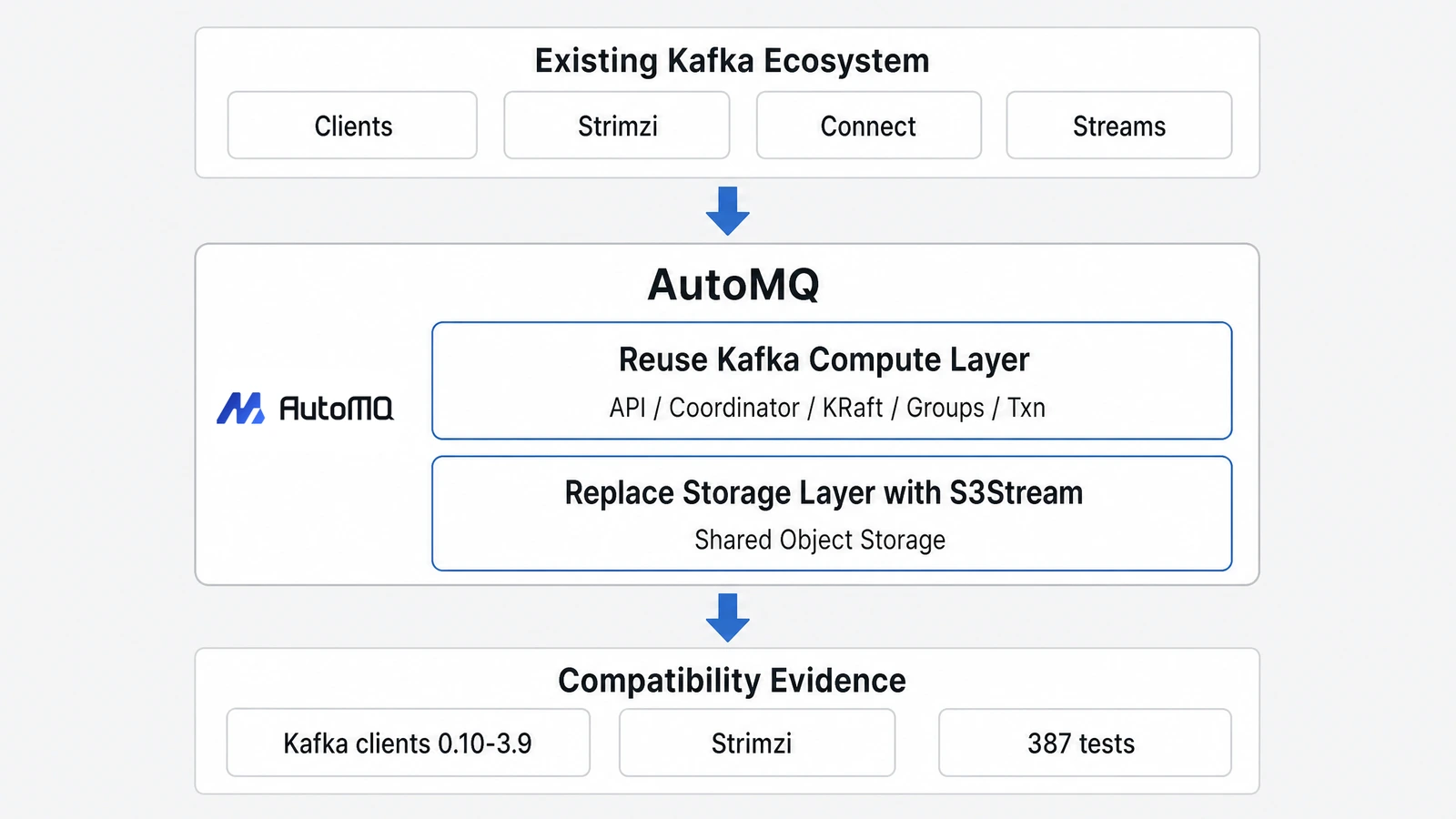
更稳妥的切面,是只替换存储层。计算层继续由 Kafka 处理 Kafka 的协议和语义,存储层用云原生方式解决本地磁盘带来的成本和弹性问题。这个判断也是 AutoMQ 这类 Kafka-compatible 云原生流存储系统的切入点:不重新发明 Kafka API,而是在保留 Kafka 生态的前提下,把传统 Kafka 绑定在 broker 本地磁盘上的存储层替换为共享对象存储。
AutoMQ 对兼容性的重视,不是事后包装出来的卖点,而是来自客户投产时的真实约束。客户迁移 Kafka 时,最担心的往往不是架构图是否足够优雅,而是现有应用、客户端版本、Operator、工具链和团队运维经验还能不能继续工作。兼容性直接决定迁移风险,所以 AutoMQ 在技术取舍中优先复用 Kafka compute layer,让 Kafka 继续处理协议、Coordinator、KRaft、事务和 Consumer group 等上层语义,再用 S3Stream 替换本地 Log storage。
这样做的好处不只是“代码复用”,而是把兼容性风险限制在更合理的边界内。在实现上,AutoMQ 的协议兼容路径复用了 Kafka 约 98% 的计算层代码,并把主要改造集中在存储层。为了让上层 Kafka 逻辑继续看到熟悉的 Log/Segment 语义,AutoMQ 通过 storage aspect、Segment/Slice 映射等机制承接底层存储变化。云原生存储负责解决云上的存储问题,Kafka 计算层继续处理 Kafka 自己最复杂的语义。
落到生产环境里,兼容性不是一句抽象承诺,而是一组团队每天会用到的能力。
| 兼容性维度 | 为什么重要 | AutoMQ 的路径 |
|---|---|---|
| Core codebase | API 和语义变化主要发生在计算层,重写会持续追赶上游 | 复用 Kafka compute layer,只替换 storage layer |
| Transactional / Compacted Topics | 这些是生产系统最容易踩边界语义的地方 | 保留 Kafka 上层语义,避免重新模拟行为 |
| Strimzi / K8s Ops | 平台团队依赖现有 Operator 和运维路径 | 支持通过 Strimzi Operator 部署多节点集群 |
| Client SDKs | 客户端版本和语言生态决定迁移成本 | 支持 Kafka clients 0.10 到 3.9,覆盖主流语言 |
所以,“支持 Kafka API”还不够。依赖 Kubernetes 原生 Kafka 运维体系的团队,会关心 Strimzi 能否继续使用;维护多语言业务的团队,会关心历史客户端能否继续连接;使用事务或 Log compaction 的场景,会关心边界语义是否一致。这些问题比一张架构图更接近真实迁移风险。
测试也要回答同一个问题。AutoMQ 已通过 Apache Kafka KRaft 模式下的 387 个原生 system test cases,覆盖消息收发、Consumer management、Topic compaction、客户端兼容、Partition reassignment、Rolling restart、Streams 和 Connect 等场景。这些测试不是锦上添花,而是在证明一件事:当 Kafka 的行为越来越复杂时,Diskless Kafka 不能只做到一次性兼容,还要能持续跟上上游生态。
100% Kafka 兼容性决定 Diskless Kafka 能不能生产落地
回到最初的问题:Kafka 在云上变重,并不意味着用户想离开 Kafka。很多团队真正想要的是保留 Kafka 的协议、语义、工具链和团队经验,同时摆脱本地磁盘架构在云上的成本和弹性负担。100% Kafka 兼容性之所以重要,就在这里:它决定 Diskless Kafka 是一次平滑的架构升级,还是一次高风险的平台替换。
如果你正在评估 Kafka 降本、弹性扩缩容,或者准备从传统 Kafka 迁移到 Diskless architecture,可以先从兼容性开始验证:现有客户端能否直接连接,Operator 和运维工具能否继续使用,事务、compaction、Consumer group 和 Connect/Streams 是否按预期工作。也可以通过 AutoMQ Cloud 创建测试环境,用现有 Kafka 应用和工具链做一次真实兼容性验证。